
AI工具分类: AI模型测评
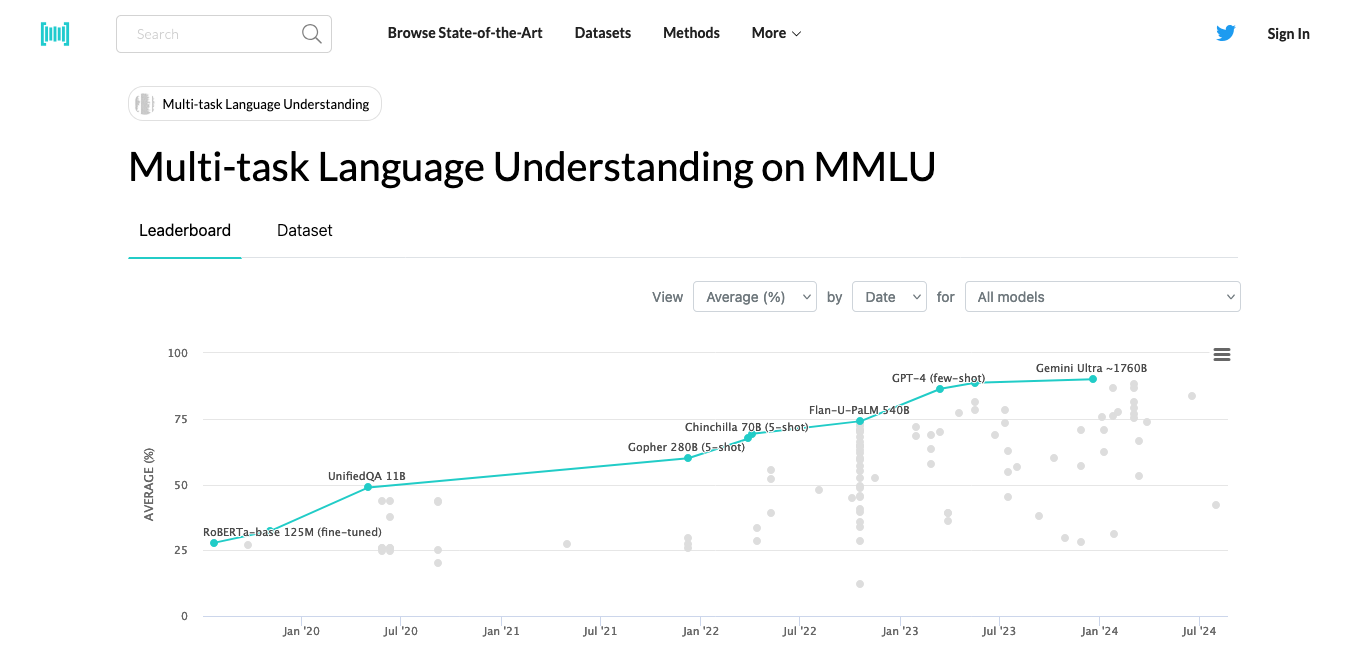
MMLU
MMLU是评估AI大模型语言理解能力的重要工具,涵盖57项多学科任务。了解MMLU如何测试AI在数学、历史、计算机科学等领域的知识和理解能力。
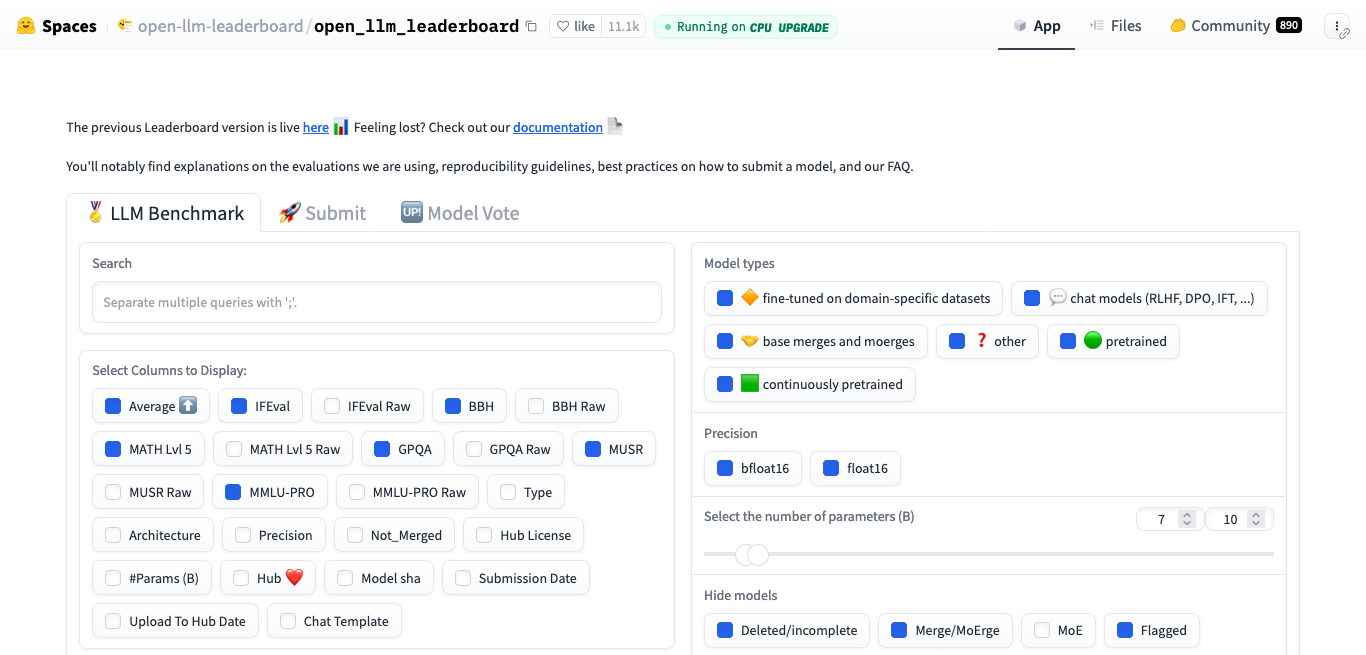
Open LLM Leaderboard
探索HuggingFace的Open LLM Leaderboard,一个用于评估开源大型语言模型性能的平台。了解其采用的四大关键基准测试,包括AI2推理挑战、HellaSwag、MMLU和TruthfulQA,如何全面评估模型能力。

C-Eval
C-Eval是一个由顶尖大学研发的中文大语言模型评估套件,涵盖52个学科和4个难度级别,通过13,948个多项选择题全面测试AI的中文理解能力。

FlagEval
FlagEval(天秤)是智源研究院开发的全面大模型评测平台,采用三维评测框架,提供30多种能力、5种任务和4大类指标的评测,涵盖600多个维度,包含84,433道题目,旨在全面评估大模型性能。
SuperCLUE
SuperCLUE是一个全面的中文大模型评测基准,从基础能力、专业能力和中文特性三个维度,评估模型在语义理解、专业知识和中文特有任务等方面的表现,涵盖70多项能力测试。
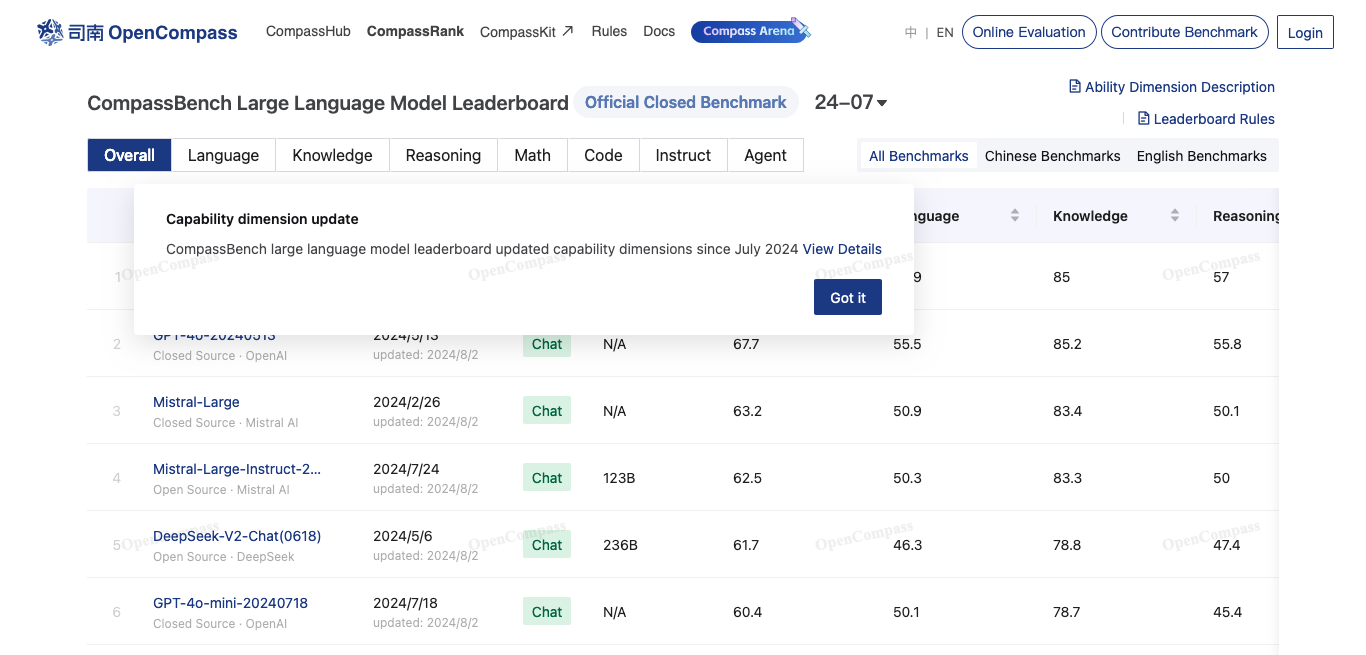
OpenCompass
OpenCompass是上海AI实验室推出的开源大模型评测系统,支持语言和多模态模型评测,定期更新榜单,为AI研究提供透明可靠的性能评估平台。
CMMLU
CMMLU是一个全面的中文语言模型评估基准,涵盖67个主题,从基础到专业领域,特别强调中国特色知识,用于测试模型的知识储备和推理能力。
MMBench
MMBench是一个由顶尖学术机构开发的创新多模态基准测试,涵盖20项细粒度能力评估,采用3000道单选题和先进评测方法,为AI领域提供全面、准确的性能衡量标准。

HELM
HELM是斯坦福大学开发的语言模型整体评估系统,通过场景、适配和指标三个模块,全面评估英语语言模型在准确率、鲁棒性等7个方面的表现,涵盖问答、摘要等多种任务。

Chatbot Arena
Chatbot Arena是一个创新的大型语言模型评估平台,通过众包匿名对战方式比较模型性能。用户可参与评判,体验多轮对话,深入了解AI模型能力。由顶尖大学研究组织LMSYS Org开发,使用Elo评分系统进行公正评估。
LLMEval3
LLMEval-3是复旦大学NLP实验室推出的最新大模型评测基准,专注于评估模型在13个学科门类、50多个二级学科的专业知识能力,包含约20万道标准生成式问答题目。

H2O EvalGPT
H2O EvalGPT是一款开放的大语言模型评估工具,提供全面的性能比较和详细排行榜。它具有相关性强、透明度高、更新迅速、覆盖范围广等特点,帮助用户选择最适合的模型来完成特定任务。
PubMedQA
探索PubMedQA:包含273,500个问答实例的全面生物医学数据集,涵盖专家标注、未标注和人工生成数据。查看18个模型的医学测试排行榜,助力生物医学自然语言处理研究。